本文共 22543 字,大约阅读时间需要 75 分钟。
之前在看DETR这篇论文中的self_attention,然后结合之前实验室组会经常提起的注意力机制,所以本周时间对注意力机制进行了相关的梳理,以及相关的源码阅读了解其实现的机制
一、注意力机制(attention mechanism)
attention机制可以它认为是一种资源分配的机制,可以理解为对于原本平均分配的资源根据attention对象的重要程度重新分配资源,重要的单位就多分一点,不重要或者不好的单位就少分一点,在深度神经网络的结构设计中,attention所要分配的资源基本上就是权重了
视觉注意力分为几种,核心思想是基于原有的数据找到其之间的关联性,然后突出其某些重要特征,有通道注意力,像素注意力,多阶注意力等,也有把NLP中的自注意力引入。
二、自注意力(self-attention)
参考文献:
参考资料:
GitHub:
自注意力有时候也称为内部注意力,是一个与单个序列的不同位置相关的注意力机制,目的是计算序列的表达形式,因为解码器的位置不变性,以及在DETR中,每个像素不仅仅包含数值信息,并且每个像素的位置信息也很重要。

所有的编码器在结构上都是相同的,但它们没有共享参数。每个编码器都可以分解成两个子层:
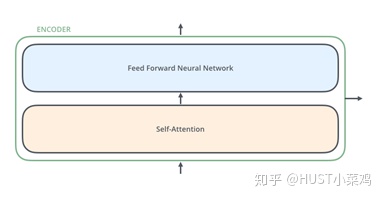
在transformer中,每个encoder子层有Multi-head self-attention和position-wise FFN组成。

输入的每个单词通过嵌入的方式形成词向量,通过自注意进行编码,然后再送入FFN得出一个层级的编码。
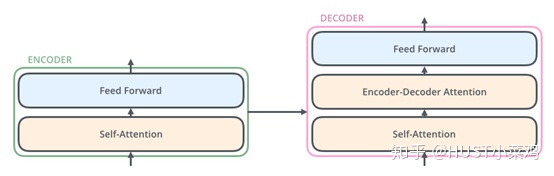
解码器在结构上也是多个相同的堆叠而成,在有和encoder相似的结构的Multi-head self-attention和position-wise FFN,同时还多了一个注意力层用来关注输入句子的相关部分。
Self-Attention
Self-Attention是Transformer最核心的内容,可以理解位将队列和一组值与输入对应,即形成querry,key,value向output的映射,output可以看作是value的加权求和,加权值则是由Self-Attention来得出的。
具体实施细节如下:
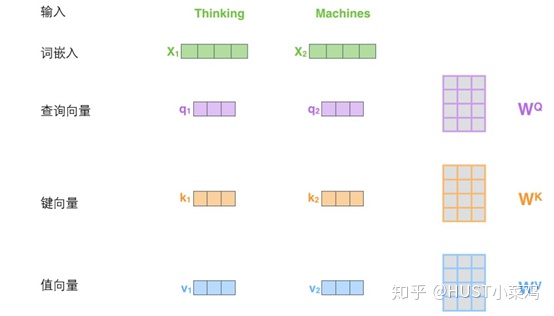
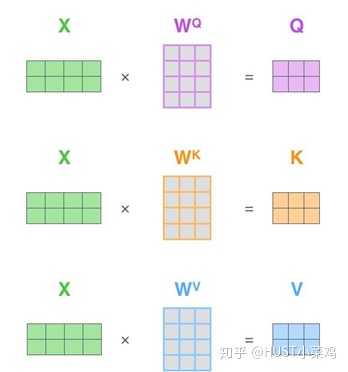
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量,Key向量和Value向量,长度均是64。它们是通过3个不同的权值矩阵由嵌入向量X乘以三个不同的权值矩阵得到,其中三个矩阵的尺寸也是相同的。均是512×64。
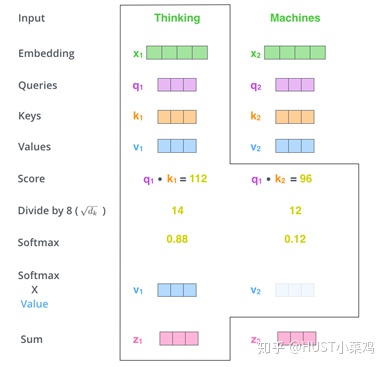
Self_attention的计算过程如下
- 将输入单词转化成嵌入向量;
- 根据嵌入向量得到q,k,v三个向量;
- 为每个向量计算一个score:score=q×v;
- 为了梯度的稳定,Transformer使用了score归一化,即除以 ;
- 对score施以softmax激活函数;
- softmax点乘Value值v,得到加权的每个输入向量的评分v;
- 相加之后得到最终的输出结果z。
矩阵形式的计算过程:
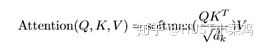
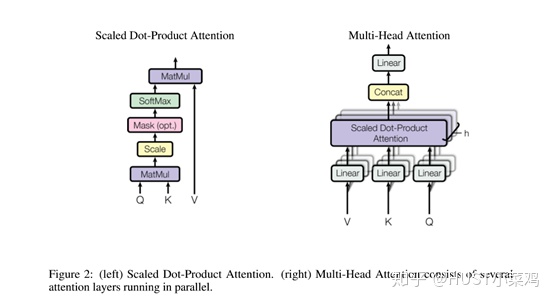
对于Multi-head self-attention,通过论文可以看出就是将单个点积注意力进行融合,两者相结合得出了transformer
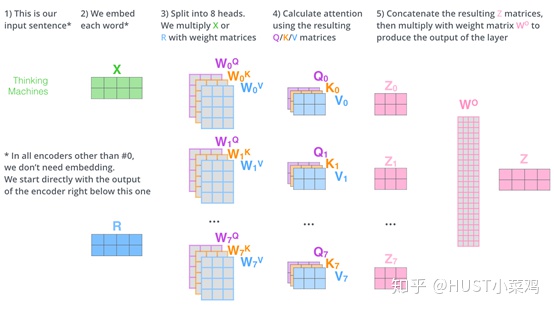
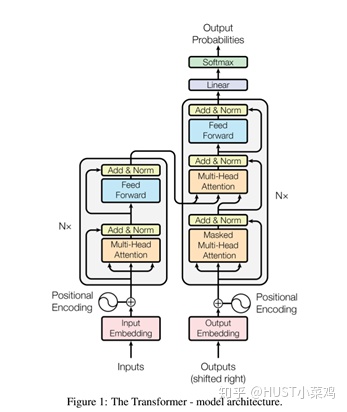
具体的实施可以参照detr的models/transformer
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved"""DETR Transformer class.Copy-paste from torch.nn.Transformer with modifications: * positional encodings are passed in MHattention * extra LN at the end of encoder is removed * decoder returns a stack of activations from all decoding layers"""import copyfrom typing import Optional, Listimport torchimport torch.nn.functional as Ffrom torch import nn, Tensorclass Transformer(nn.Module): def __init__(self, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False, return_intermediate_dec=False): super().__init__() encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, activation, normalize_before) encoder_norm = nn.LayerNorm(d_model) if normalize_before else None self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm) decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout, activation, normalize_before) decoder_norm = nn.LayerNorm(d_model) self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm, return_intermediate=return_intermediate_dec) self._reset_parameters() self.d_model = d_model self.nhead = nhead def _reset_parameters(self): for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p) def forward(self, src, mask, query_embed, pos_embed): # flatten NxCxHxW to HWxNxC bs, c, h, w = src.shape src = src.flatten(2).permute(2, 0, 1) pos_embed = pos_embed.flatten(2).permute(2, 0, 1) query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1) mask = mask.flatten(1) tgt = torch.zeros_like(query_embed) memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed) hs = self.decoder(tgt, memory, memory_key_padding_mask=mask, pos=pos_embed, query_pos=query_embed) return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)class TransformerEncoder(nn.Module): def __init__(self, encoder_layer, num_layers, norm=None): super().__init__() self.layers = _get_clones(encoder_layer, num_layers) self.num_layers = num_layers self.norm = norm def forward(self, src, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): output = src for layer in self.layers: output = layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask, pos=pos) if self.norm is not None: output = self.norm(output) return outputclass TransformerDecoder(nn.Module): def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False): super().__init__() self.layers = _get_clones(decoder_layer, num_layers) self.num_layers = num_layers self.norm = norm self.return_intermediate = return_intermediate def forward(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): output = tgt intermediate = [] for layer in self.layers: output = layer(output, memory, tgt_mask=tgt_mask, memory_mask=memory_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask, pos=pos, query_pos=query_pos) if self.return_intermediate: intermediate.append(self.norm(output)) if self.norm is not None: output = self.norm(output) if self.return_intermediate: intermediate.pop() intermediate.append(output) if self.return_intermediate: return torch.stack(intermediate) return outputclass TransformerEncoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) # Implementation of Feedforward model self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.activation = _get_activation_fn(activation) self.normalize_before = normalize_before def with_pos_embed(self, tensor, pos: Optional[Tensor]): return tensor if pos is None else tensor + pos def forward_post(self, src, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): q = k = self.with_pos_embed(src, pos) src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0] src = src + self.dropout1(src2) src = self.norm1(src) src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) src = src + self.dropout2(src2) src = self.norm2(src) return src def forward_pre(self, src, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): src2 = self.norm1(src) q = k = self.with_pos_embed(src2, pos) src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0] src = src + self.dropout1(src2) src2 = self.norm2(src) src2 = self.linear2(self.dropout(self.activation(self.linear1(src2)))) src = src + self.dropout2(src2) return src def forward(self, src, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): if self.normalize_before: return self.forward_pre(src, src_mask, src_key_padding_mask, pos) return self.forward_post(src, src_mask, src_key_padding_mask, pos)class TransformerDecoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) # Implementation of Feedforward model self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.dropout3 = nn.Dropout(dropout) self.activation = _get_activation_fn(activation) self.normalize_before = normalize_before def with_pos_embed(self, tensor, pos: Optional[Tensor]): return tensor if pos is None else tensor + pos def forward_post(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): q = k = self.with_pos_embed(tgt, query_pos) tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0] tgt = tgt + self.dropout1(tgt2) tgt = self.norm1(tgt) tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), key=self.with_pos_embed(memory, pos), value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0] tgt = tgt + self.dropout2(tgt2) tgt = self.norm2(tgt) tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt)))) tgt = tgt + self.dropout3(tgt2) tgt = self.norm3(tgt) return tgt def forward_pre(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): tgt2 = self.norm1(tgt) q = k = self.with_pos_embed(tgt2, query_pos) tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0] tgt = tgt + self.dropout1(tgt2) tgt2 = self.norm2(tgt) tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos), key=self.with_pos_embed(memory, pos), value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0] tgt = tgt + self.dropout2(tgt2) tgt2 = self.norm3(tgt) tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2)))) tgt = tgt + self.dropout3(tgt2) return tgt def forward(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): if self.normalize_before: return self.forward_pre(tgt, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos) return self.forward_post(tgt, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)def _get_clones(module, N): return nn.ModuleList([copy.deepcopy(module) for i in range(N)])def build_transformer(args): return Transformer( d_model=args.hidden_dim, dropout=args.dropout, nhead=args.nheads, dim_feedforward=args.dim_feedforward, num_encoder_layers=args.enc_layers, num_decoder_layers=args.dec_layers, normalize_before=args.pre_norm, return_intermediate_dec=True, )def _get_activation_fn(activation): """Return an activation function given a string""" if activation == "relu": return F.relu if activation == "gelu": return F.gelu if activation == "glu": return F.glu raise RuntimeError(F"activation should be relu/gelu, not {activation}.") 三、软注意力(soft-attention)
软注意力是一个[0,1]间的连续分布问题,更加关注区域或者通道,软注意力是确定性注意力,学习完成后可以通过网络生成,并且是可微的,可以通过神经网络计算出梯度并且可以前向传播和后向反馈来学习得到注意力的权重。
1、空间域注意力(spatial transformer network)
论文地址:
GitHub地址:
空间区域注意力可以理解为让神经网络在看哪里。通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息,在很多现有的方法中都有使用这种网络,自己接触过的一个就是ALPHA Pose。spatial transformer其实就是注意力机制的实现,因为训练出的spatial transformer能够找出图片信息中需要被关注的区域,同时这个transformer又能够具有旋转、缩放变换的功能,这样图片局部的重要信息能够通过变换而被框盒提取出来。
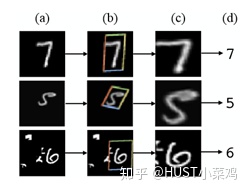
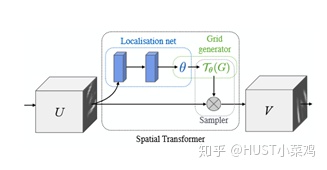
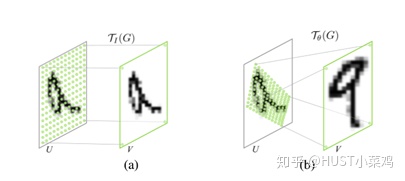
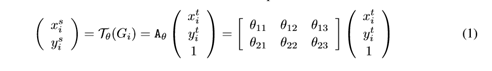
主要在于空间变换矩阵的学习
class STN(Module): def __init__(self, layout = 'BHWD'): super(STN, self).__init__() if layout == 'BHWD': self.f = STNFunction() else: self.f = STNFunctionBCHW() def forward(self, input1, input2): return self.f(input1, input2)class STNFunction(Function): def forward(self, input1, input2): self.input1 = input1 self.input2 = input2 self.device_c = ffi.new("int *") output = torch.zeros(input1.size()[0], input2.size()[1], input2.size()[2], input1.size()[3]) #print('decice %d' % torch.cuda.current_device()) if input1.is_cuda: self.device = torch.cuda.current_device() else: self.device = -1 self.device_c[0] = self.device if not input1.is_cuda: my_lib.BilinearSamplerBHWD_updateOutput(input1, input2, output) else: output = output.cuda(self.device) my_lib.BilinearSamplerBHWD_updateOutput_cuda(input1, input2, output, self.device_c) return output def backward(self, grad_output): grad_input1 = torch.zeros(self.input1.size()) grad_input2 = torch.zeros(self.input2.size()) #print('backward decice %d' % self.device) if not grad_output.is_cuda: my_lib.BilinearSamplerBHWD_updateGradInput(self.input1, self.input2, grad_input1, grad_input2, grad_output) else: grad_input1 = grad_input1.cuda(self.device) grad_input2 = grad_input2.cuda(self.device) my_lib.BilinearSamplerBHWD_updateGradInput_cuda(self.input1, self.input2, grad_input1, grad_input2, grad_output, self.device_c) return grad_input1, grad_input2 2、通道注意力(Channel Attention,CA)
通道注意力可以理解为让神经网络在看什么,典型的代表是SENet。卷积网络的每一层都有好多卷积核,每个卷积核对应一个特征通道,相对于空间注意力机制,通道注意力在于分配各个卷积通道之间的资源,分配粒度上比前者大了一个级别。
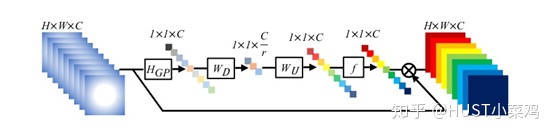
论文:Squeeze-and-Excitation Networks()
GitHub地址:
Squeeze操作:将各通道的全局空间特征作为该通道的表示,使用全局平均池化生成各通道的统计量
Excitation操作:学习各通道的依赖程度,并根据依赖程度对不同的特征图进行调整,得到最后的输出,需要考察各通道的依赖程度
整体的结构如图所示:
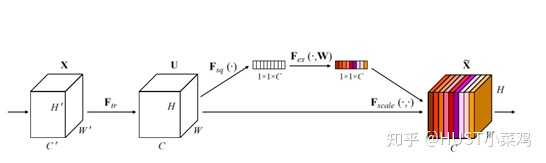
卷积层的输出并没有考虑对各通道的依赖,SEBlock的目的在于然根网络选择性的增强信息量最大的特征,是的后期处理充分利用这些特征并抑制无用的特征。
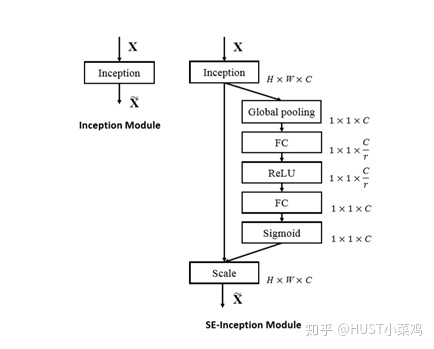
SE-Inception Module
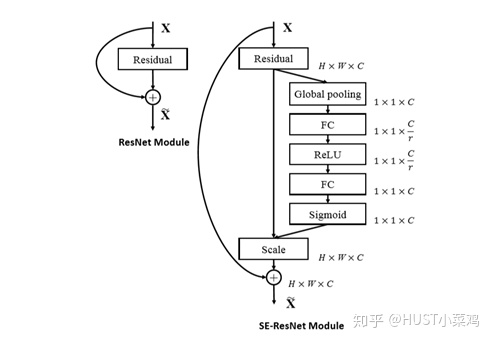
SE-ResNet Module
- 将输入特征进行 Global avgpooling,得到1×1×Channel
- 然后bottleneck特征交互一下,先压缩channel数,再重构回channel数
- 最后接个sigmoid,生成channel间0~1的attention weights,最后scale乘回原输入特征
SE-ResNet的SE-Block
class SEBasicBlock(nn.Module): expansion = 1 def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, base_width=64, dilation=1, norm_layer=None, *, reduction=16): super(SEBasicBlock, self).__init__() self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = nn.BatchNorm2d(planes) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes, 1) self.bn2 = nn.BatchNorm2d(planes) self.se = SELayer(planes, reduction) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.se(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return outclass SELayer(nn.Module): def __init__(self, channel, reduction=16): super(SELayer, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Sequential( nn.Linear(channel, channel // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x).view(b, c) y = self.fc(y).view(b, c, 1, 1) return x * y.expand_as(x)
ResNet的Basic Block
class BasicBlock(nn.Module): def __init__(self, inplanes, planes, stride=1): super(BasicBlock, self).__init__() self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = nn.BatchNorm2d(planes) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes) self.bn2 = nn.BatchNorm2d(planes) if inplanes != planes: self.downsample = nn.Sequential(nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes)) else: self.downsample = lambda x: x self.stride = stride def forward(self, x): residual = self.downsample(x) out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out += residual out = self.relu(out) return out
两者的差别主要体现在多了一个SElayer,详细可以查看源码
3、混合域模型(融合空间域和通道域注意力)
(1)论文:Residual Attention Network for image classification()
文章中注意力的机制是软注意力基本的加掩码(mask)机制,但是不同的是,这种注意力机制的mask借鉴了残差网络的想法,不只根据当前网络层的信息加上mask,还把上一层的信息传递下来,这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题。
该文章的注意力机制的创新点在于提出了残差注意力学习(residual attention learning),不仅只把mask之后的特征张量作为下一层的输入,同时也将mask之前的特征张量作为下一层的输入,这时候可以得到的特征更为丰富,从而能够更好的注意关键特征。同时采用三阶注意力模块来构成整个的注意力。
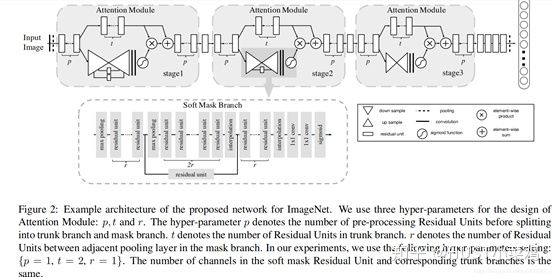
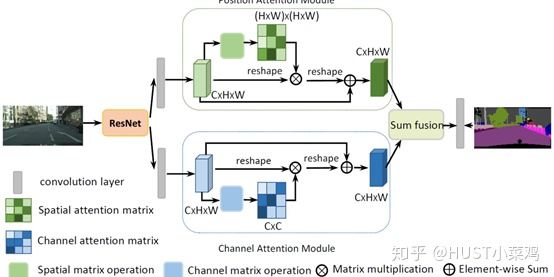
(2)Dual Attention Network for Scene Segmentation()
4、Non-Local
论文:non-local neural networks()
GitHub地址:
Local这个词主要是针对感受野(receptive field)来说的。以单一的卷积操作为例,它的感受野大小就是卷积核大小,而我们一般都选用3*3,5*5之类的卷积核,它们只考虑局部区域,因此都是local的运算。同理,池化(Pooling)也是。相反的,non-local指的就是感受野可以很大,而不是一个局部领域。全连接就是non-local的,而且是global的。但是全连接带来了大量的参数,给优化带来困难。卷积层的堆叠可以增大感受野,但是如果看特定层的卷积核在原图上的感受野,它毕竟是有限的。这是local运算不能避免的。然而有些任务,它们可能需要原图上更多的信息,比如attention。如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息。
文章定义的对于神经网络通用的Non-Local计算如下所示:
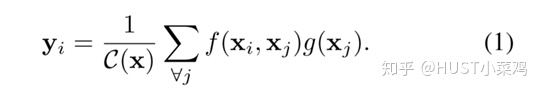
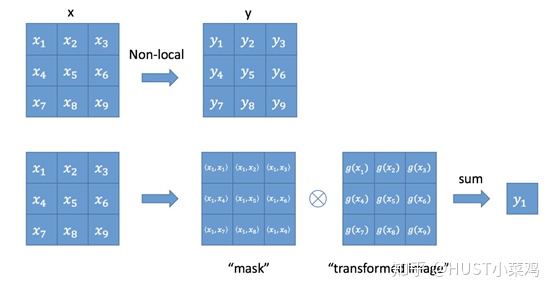
如果按照上面的公式,用for循环实现肯定是很慢的。此外,如果在尺寸很大的输入上应用non-local layer,也是计算量很大的。后者的解决方案是,只在高阶语义层中引入non-local layer。还可以通过对embedding(θ,ϕ,g)的结果加pooling层来进一步地减少计算量。
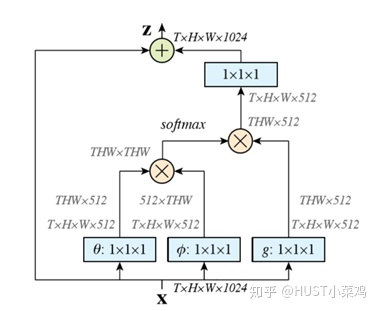
- 首先对输入的 feature map X 进行线性映射(通过1x1卷积,来压缩通道数),然后得到θ,ϕ,g特征
- 通过reshape操作,强行合并上述的三个特征除通道数外的维度,然后对 进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系)
- 然后对自相关特征 以列or以行(具体看矩阵 g 的形式而定) 进行 Softmax 操作,得到0~1的weights,这里就是我们需要的 Self-attention 系数
- 最后将 attention系数,对应乘回特征矩阵g中,然后再上扩channel 数,与原输入feature map X残差
5、位置注意力(position-wise attention)
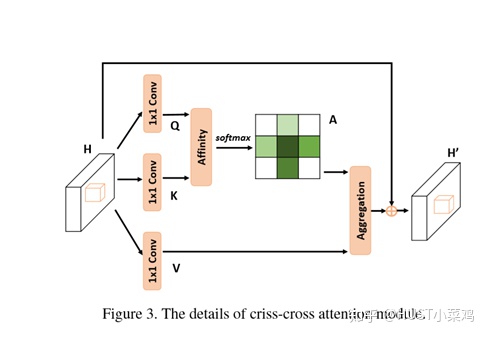
论文:CCNet: Criss-Cross Attention for Semantic Segmentation()
Github地址:
本篇文章的亮点在于用了巧妙的方法减少了参数量。在上面的DANet中,attention map计算的是所有像素与所有像素之间的相似性,空间复杂度为(HxW)x(HxW),而本文采用了criss-cross思想,只计算每个像素与其同行同列即十字上的像素的相似性,通过进行循环(两次相同操作),间接计算到每个像素与每个像素的相似性,将空间复杂度降为(HxW)x(H+W-1)
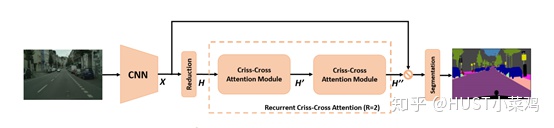
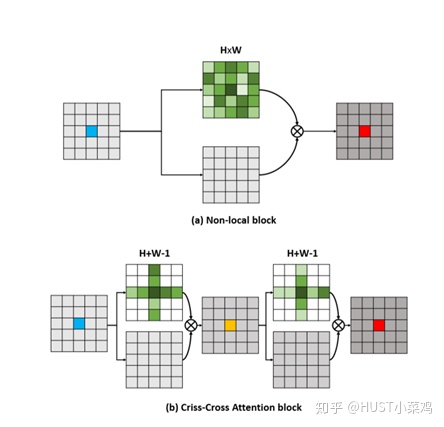
在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。和non-local的方法相比极大的降低了计算量,同时采用二阶注意力,能够从所有像素中获取全图像的上下文信息,以生成具有密集且丰富的上下文信息的新特征图。在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
def _check_contiguous(*args): if not all([mod is None or mod.is_contiguous() for mod in args]): raise ValueError("Non-contiguous input")class CA_Weight(autograd.Function): @staticmethod def forward(ctx, t, f): # Save context n, c, h, w = t.size() size = (n, h+w-1, h, w) weight = torch.zeros(size, dtype=t.dtype, layout=t.layout, device=t.device) _ext.ca_forward_cuda(t, f, weight) # Output ctx.save_for_backward(t, f) return weight @staticmethod @once_differentiable def backward(ctx, dw): t, f = ctx.saved_tensors dt = torch.zeros_like(t) df = torch.zeros_like(f) _ext.ca_backward_cuda(dw.contiguous(), t, f, dt, df) _check_contiguous(dt, df) return dt, dfclass CA_Map(autograd.Function): @staticmethod def forward(ctx, weight, g): # Save context out = torch.zeros_like(g) _ext.ca_map_forward_cuda(weight, g, out) # Output ctx.save_for_backward(weight, g) return out @staticmethod @once_differentiable def backward(ctx, dout): weight, g = ctx.saved_tensors dw = torch.zeros_like(weight) dg = torch.zeros_like(g) _ext.ca_map_backward_cuda(dout.contiguous(), weight, g, dw, dg) _check_contiguous(dw, dg) return dw, dgca_weight = CA_Weight.applyca_map = CA_Map.applyclass CrissCrossAttention(nn.Module): """ Criss-Cross Attention Module""" def __init__(self,in_dim): super(CrissCrossAttention,self).__init__() self.chanel_in = in_dim self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1) self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1) self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1) self.gamma = nn.Parameter(torch.zeros(1)) def forward(self,x): proj_query = self.query_conv(x) proj_key = self.key_conv(x) proj_value = self.value_conv(x) energy = ca_weight(proj_query, proj_key) attention = F.softmax(energy, 1) out = ca_map(attention, proj_value) out = self.gamma*out + x return out__all__ = ["CrissCrossAttention", "ca_weight", "ca_map"] 三、强注意力(hard attention)
0/1问题,哪些被attention,哪些不被attention。更加关注点,图像中的每个点都可能延伸出注意力,同时强注意力是一个随机预测的过程,更加强调动态变化,并且是不可微,所以训练过程往往通过增强学习。
参考资料
编辑于 11-09
转载地址:http://ukuii.baihongyu.com/